
Kafka & Kafka Streams
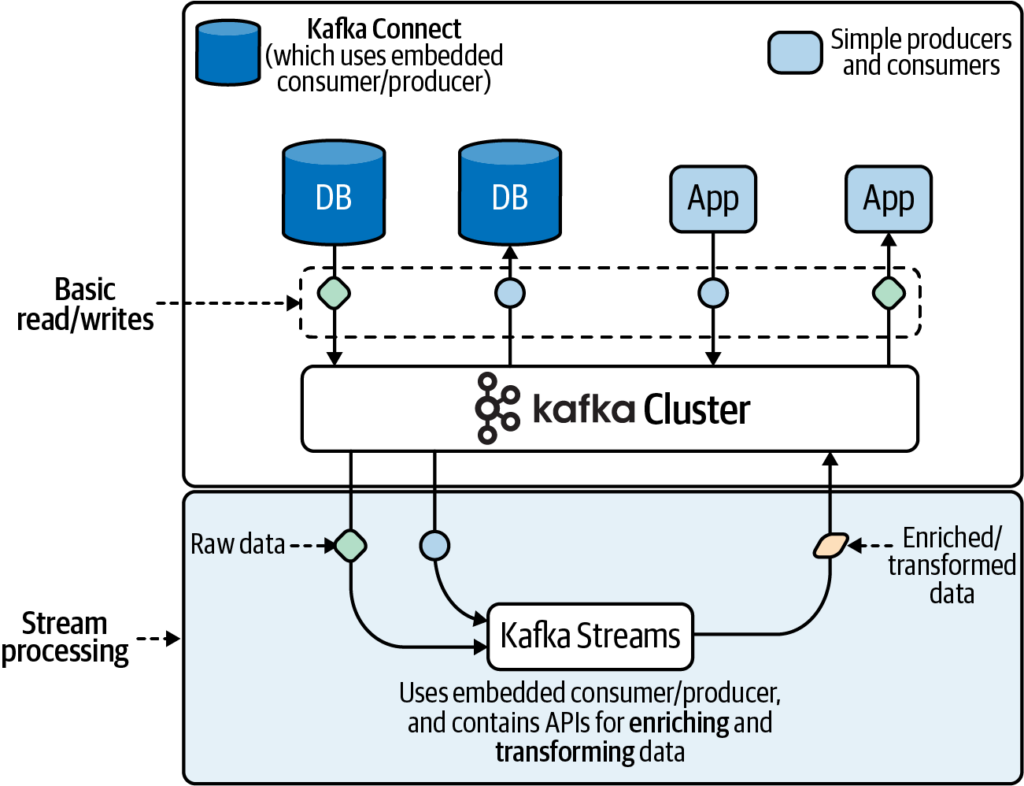
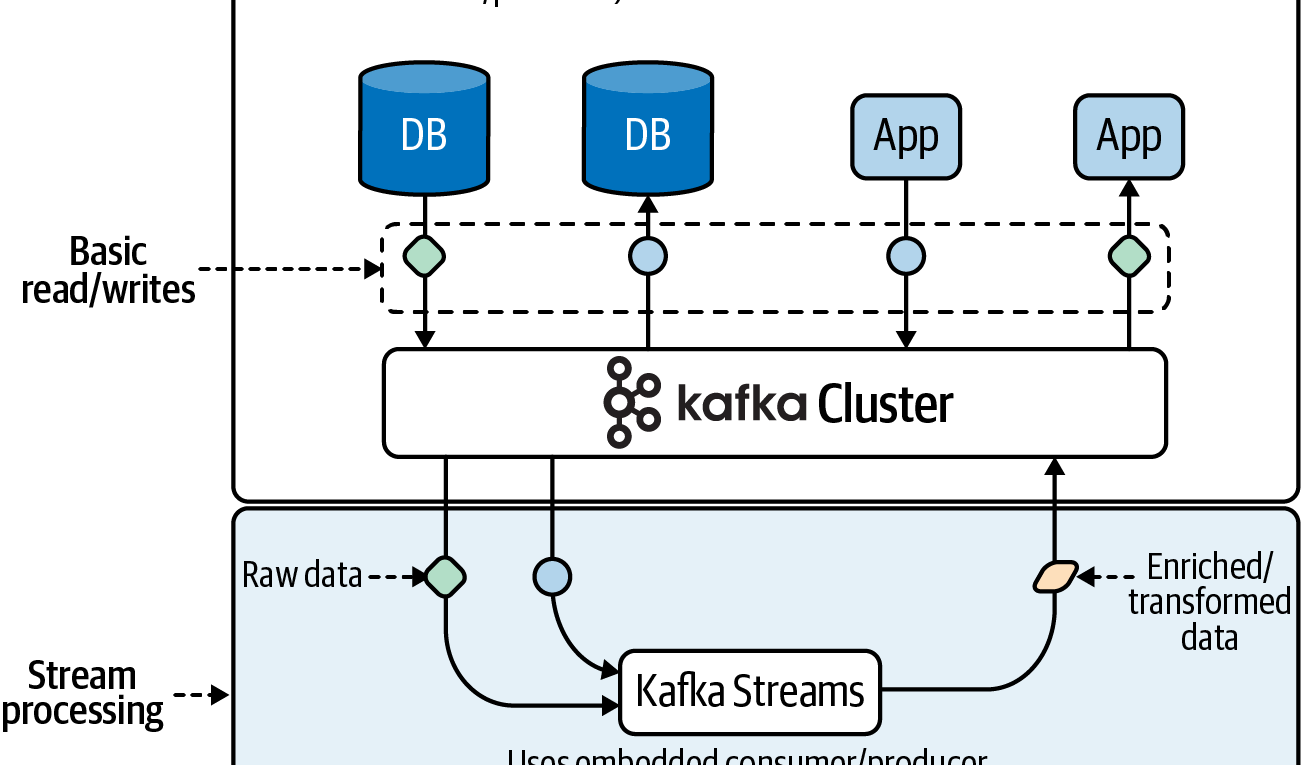
Kafka Streams operates at an exciting layer of the Kafka ecosystem: the place where data from many sources converges. This is the layer where sophisticated data enrichment, transformation, and processing can happen. It’s the same place where, in a pre–Kafka Streams world, we would have tediously written our own stream processing abstractions (using the Consumer/Producer API approach) or absorbed a complexity hit by using another framework. Now, let’s get a first look at the features of Kafka Streams that allow us to operate at this layer in a fun and efficient way.
Kafka Stream features
- A high-level DSL that looks and feels like Java’s streaming API. The DSL provides a fluent and functional approach to processing data streams that is easy to learn and use.
- A low-level Processor API that gives developers fine-grained control when they need it.
- Convenient abstractions for modeling data as either streams or tables.
- The ability to join streams and tables, which is useful for data transformation and enrichment.
- Operators and utilities for building both stateless and stateful stream processing applications.
- Support for time-based operations, including windowing and periodic functions.
- Easy installation. It’s just a library, so you can add Kafka Streams to any Java application.7
- Scalability, reliability, maintainability.
In Martin Kleppmann’s excellent book, Designing Data-Intensive Applications (O’Reilly), the author highlights three important goals for data systems:
- Scalability
- Reliability
- Maintainability
Apache Beam–driven pipelines lack some important features that are offered in Kafka Streams. Robert Yokota, who created an experimental Kafka Streams Beam Runner and who maintains several innovative projects in the Kafka ecosystem,13 puts it this way in his comparison of different streaming frameworks:
One way to state the differences between the two systems is as follows:
- Kafka Streams is a stream-relational processing platform.
- Apache Beam is a stream-only processing platform.
A stream-relational processing platform has the following capabilities which are typically missing in a stream-only processing platform:
- Relations (or tables) are first-class citizens, i.e., each has an independent identity.
- Relations can be transformed into other relations.
- Relations can be queried in an ad-hoc manner.
Processor Topologies
Kafka Streams leverages a programming paradigm called dataflow programming (DFP), which is a data-centric method of representing programs as a series of inputs, outputs, and processing stages. This leads to a very natural and intuitive way of creating stream processing programs and is one of the many reasons I think Kafka Streams is easy to pick up for beginners.