
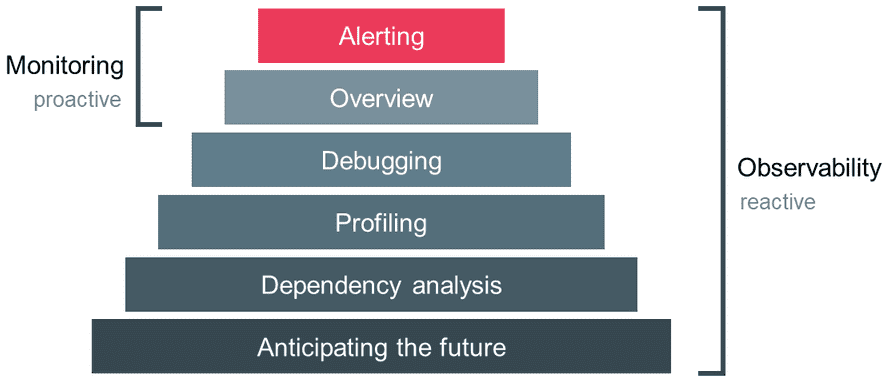
System observability and monitoring
Scuba
Not all the applications need joins

Deep systems
Systems must provide SLO (Service Level Objectives) to define OKRs (you can measure and improve them)
Telemetry & Control goes together
Systems are designed to scale only up to 3 orders of magnitude
Systems tend to become deep over time
Observability is important (How well can you infer what happens in the black box based on the telemetry)
The source of changes you make your system to become more observable also makes it more controllable
A guy
Stress is responsibility without control
Some dude
Traces are not sprinkles, they won’t solve the problem by themselves, you need metrics and logs
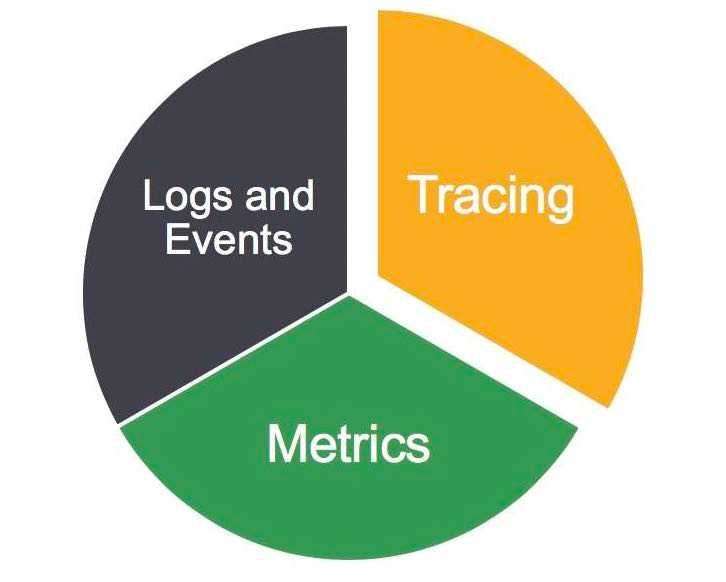
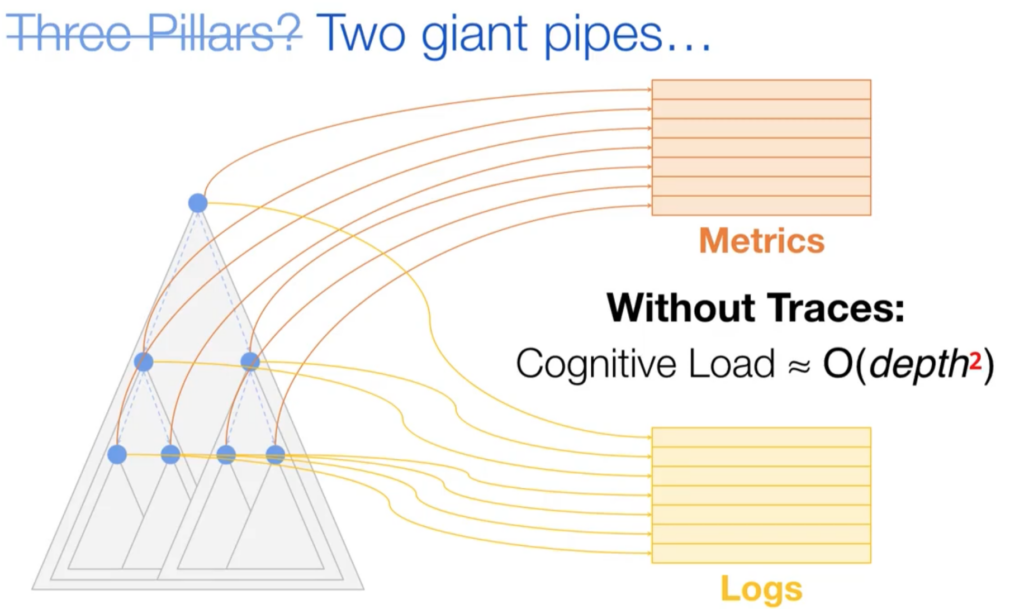
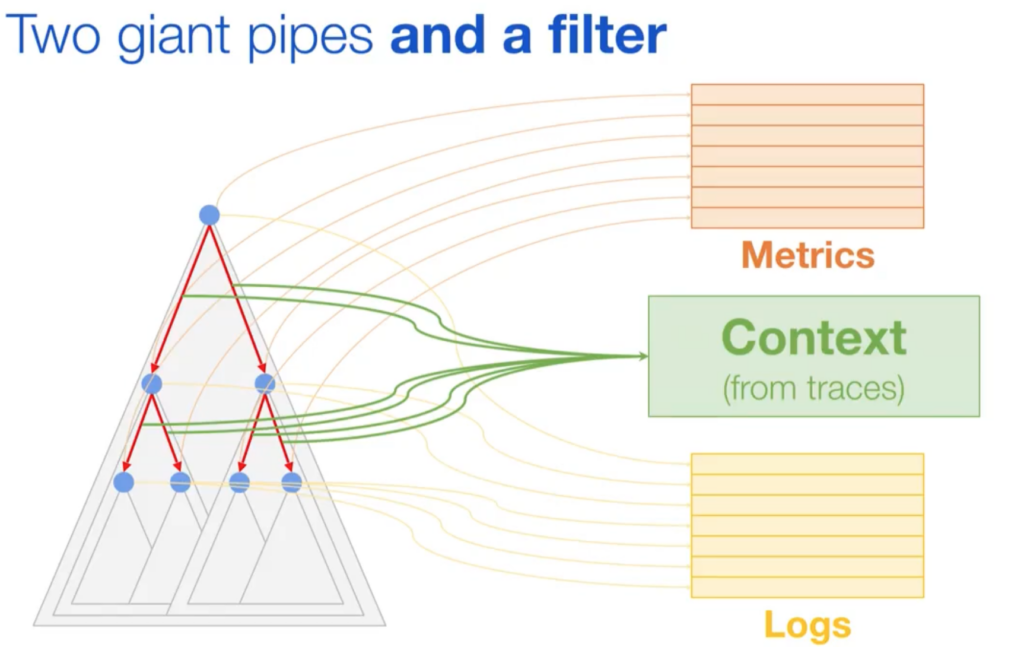
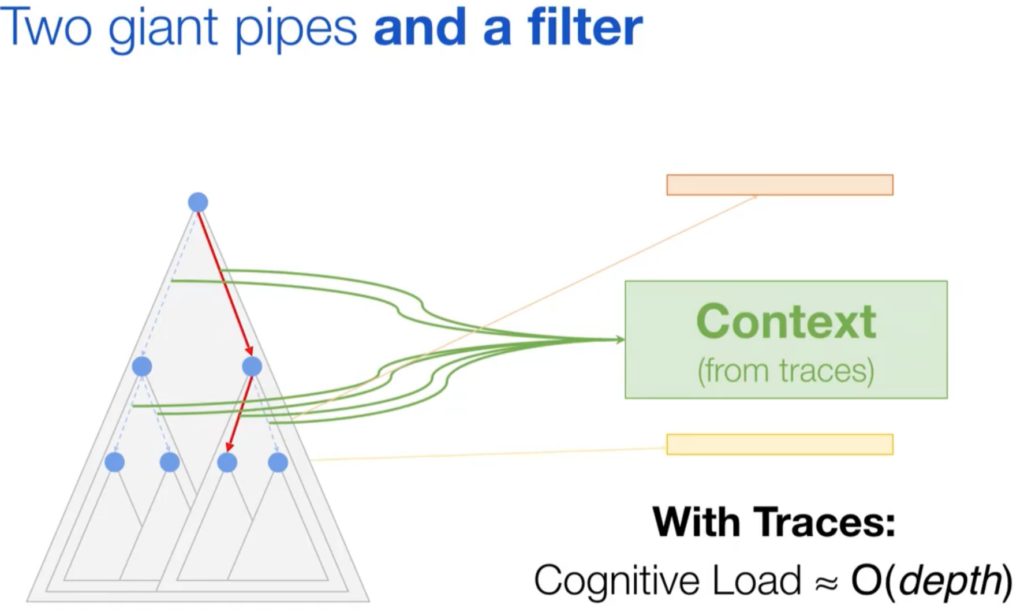
Context is important, and reduces system complexity, it is not about dashboards but about context
Context reduces the effort & complexity of the operator to focus on signals that actually matter (metrics or logs)
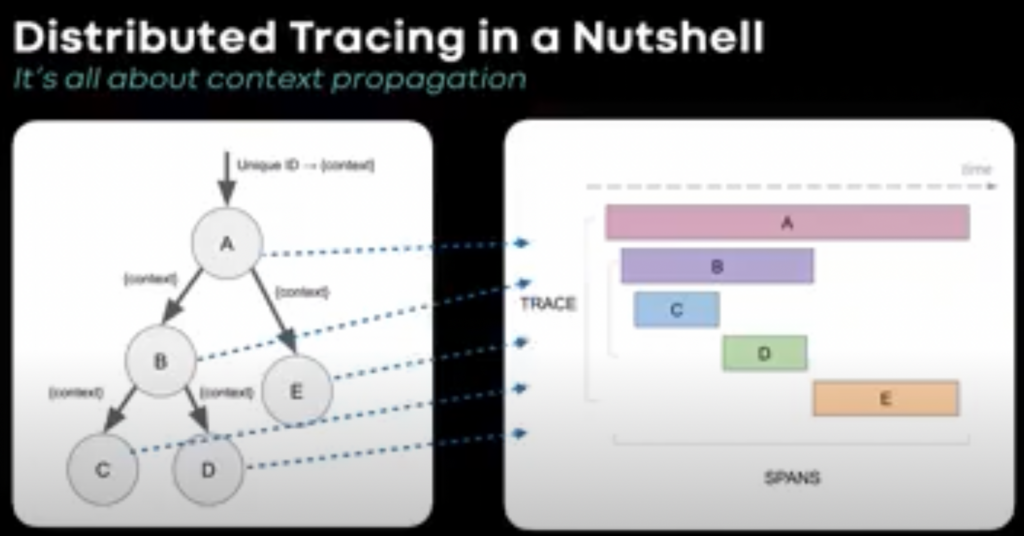
Distributed Tracing
Observability (Systems ability to answer these questions)
- What went wrong?
- Timeout?
- Errors?
- Latency?
- Something didn’t happen?
Where did it go wrong?
- where is the buttle neck
- Where are the errors
- Which services did the request go through
- What did every service do when processing the request?
Why did it go wrong?
- Network
- Resources contention
- New Code deployment
- Third-party services
Distributed Tracing captures events with context and causality
A dude
Spiros Xanthos, CEO, and Founder, Omnition
Where is the context?
Observability, it’s bigger than production
An organization where everybody can answer questions with data is an organization with powers
Etsy
A system is a regularly interconnecting or interdependent group of items forming a unified whole
Observability is an attribute of a system
Production is the environment housing the systems your users interact with directly


Your data has many dimensions and your tools need to let you explore all of them
How the teams make triage, what data sources they query
All complex software systems are also socio-technical systems. They are made up of hardware, code, and humans who maintain it
Casey Rosenthal, Inhumanity of Root Cause Analysis
there are sticking similarities between questions a business might want answered and questions software engineers might want answered during debugging
Cindy Shridharan, Distributed Systems Observability, Chapter 4
Scaling observability data at Datadog
Observability: a successful approach
Record everything you can think of:
all application and system logs
- trace all requests
- Scaling observability data at Datadog
- application metrics(USE,RED,SLOs,cost,etc)


Developing meaningful SLIs for fun and profit
Service Level Agreements
Site Reliability Engineer
Proactive > Reactive