
Data pipelines notes
EtLT
Some examples of the type of transformation that fits into the EtLT subpattern include the following:
- Deduplicate records in a table
- Parse URL parameters into individual components
- Mask or otherwise obfuscate sensitive data
These types of transforms are either fully disconnected from business logic or, in the case of something like masking sensitive data, at times required as early in a pipeline as possible for legal or security reasons. In addition, there is value in using the right tool for the right job
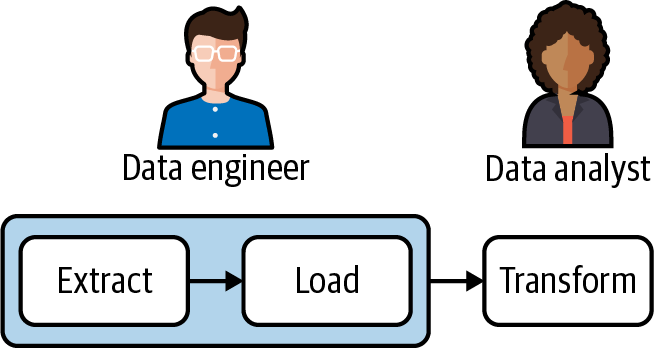
ELT for Data Analysis
ELT has become the most common and, in my opinion, most optimal pattern for pipelines built for data analysis.
With ELT, data engineers can focus on the extract and load steps in a pipeline (data ingestion), while analysts can utilize SQL to transform the data that’s been ingested as needed for reporting and analysis.
Data Ingestion: Extracting Data
Extracting Data from a RDBMS
- Full or incremental extraction using SQL
- Binary Log (binlog) replication
Full or incremental extraction using SQL is far simpler to implement, but also less scalable for large datasets with frequent changes. There are also trade-offs between full and incremental extractions that I discuss in the following section.
Binary Log replication, though more complex to implement, is better suited to cases where the data volume of changes in source tables is high, or there is a need for more frequent data ingestions from the MySQL source.
Extracting Data from a REST API
Get data from endpoint, flatten the data, treat the data as row
Data Ingestion: Loading Data
Transforming Data
Orchestrating Pipelines
workflow orchestration platforms (also referred to as workflow management systems (WMSs)
Airflow is an open source project started by Maxime Beauchemin at Airbnb in 2014. It joined the Apache Software Foundation’s Incubator program in March 2016. Airflow was built to solve a common challenge faced by data engineering teams: how to build, manage, and monitor workflows (data pipelines in particular) that involve multiple tasks with mutual dependencies.
A book
Best Practices for Maintaining Pipelines
orders_contract.json
{
ingestion_jobid: "orders_postgres",
source_host: "my_host.com",
source_db: "ecommerce",
source_table: "orders",
ingestion_type: "full",
ingestion_frequency_minutes: "60",
source_owner: "dev-team@mycompany.com",
ingestion_owner: "data-eng@mycompany.com"
};
There should be data owners from source & target and automation to detect potential schema changes to let the stakeholders know when something broke
Standardizing Data Ingestion
- Ingestion jobs must be written to handle a variety of source system types (Postgres, Kafka, and so on). The more source system types you need to ingest from, the larger your codebase and the more to maintain.
- Ingestion jobs for the same source system type cannot be easily standardized. For example, even if you only ingest from REST APIs, if those APIs do not have standardized ways of paging, incrementally accessing data, and other features, data engineers may build “one-off” ingestion jobs that don’t reuse code and share logic that can be centrally maintained.
Forging a partnership with the engineering organization requires patience and the right touch, but it’s an underrated nontechnical skill for data teams.
A book
Strive for config-driven data ingestions
Are you ingesting from a number of Postgres databases and tables? Don’t write a different job for each ingestion, but rather a single job that iterates through config files (or records in a database table!) that defines the tables and schemas you want to ingest.
Consider your own abstractions
If you can’t get source system owners to build some standardized abstractions between their systems and your ingestion, consider doing so yourself or partnering with them and taking on the bulk of the development work. For example, if you must ingest data from a Postgres or MySQL database, get permission from the source team to implement streaming CDC with Debezium rather than writing yet another ingestion job.
Dbt
When dbt run is executed, the SQL scripts representing each model will run in the proper order based on how each table is referenced from each other.
Key Pipeline Metrics
- Data integrity
- DAG successful runs
- DAG total runtime