
Data analytics & data processing

- Collection
- Processing
- Storage
- Usage
- Control
Data Analytics is an overarching practice that encompasses the complete life cycle of insight generation, from collection to quality and access control
Data processing is a component of the data Data Analytics practice. It transforms raw data into valuable insights and information.
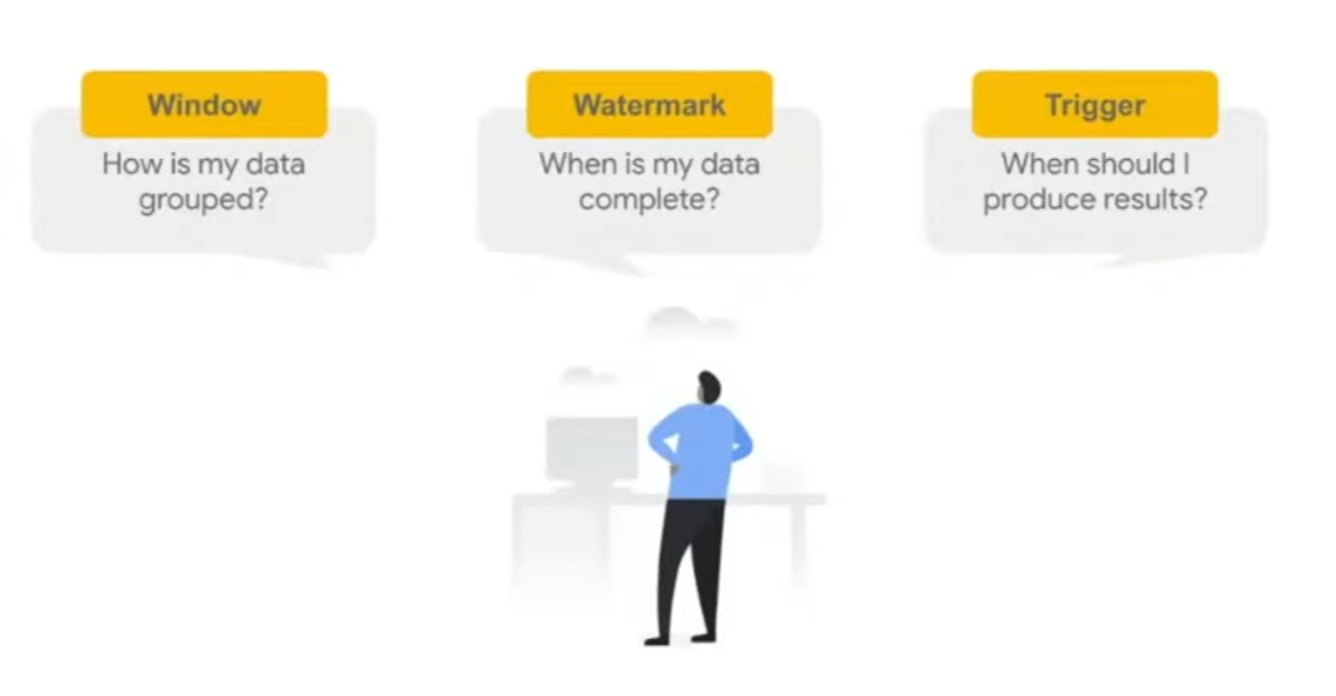
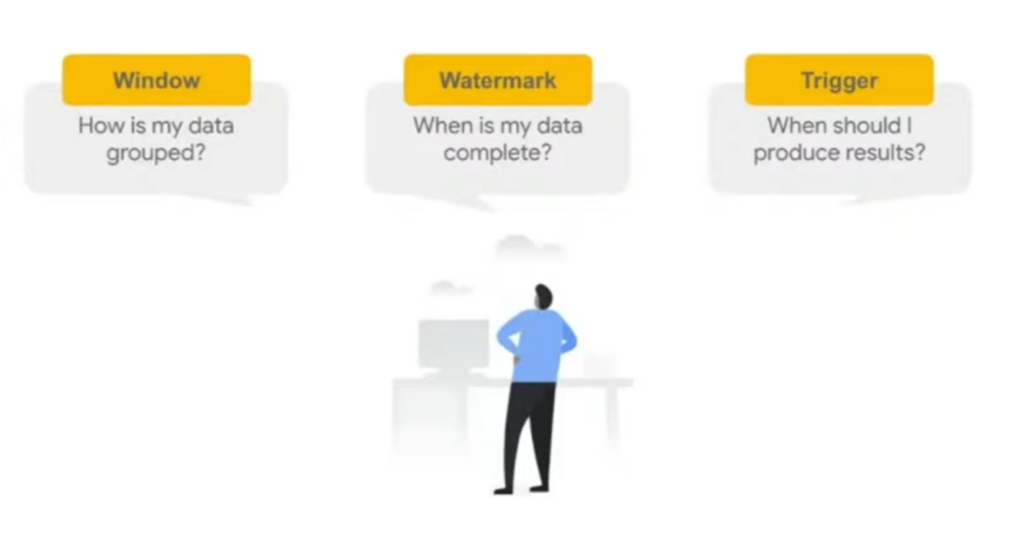
Apache beam is a programming model to build batch & streaming data processing pipelines
Beam College

Metadata driven pipelines


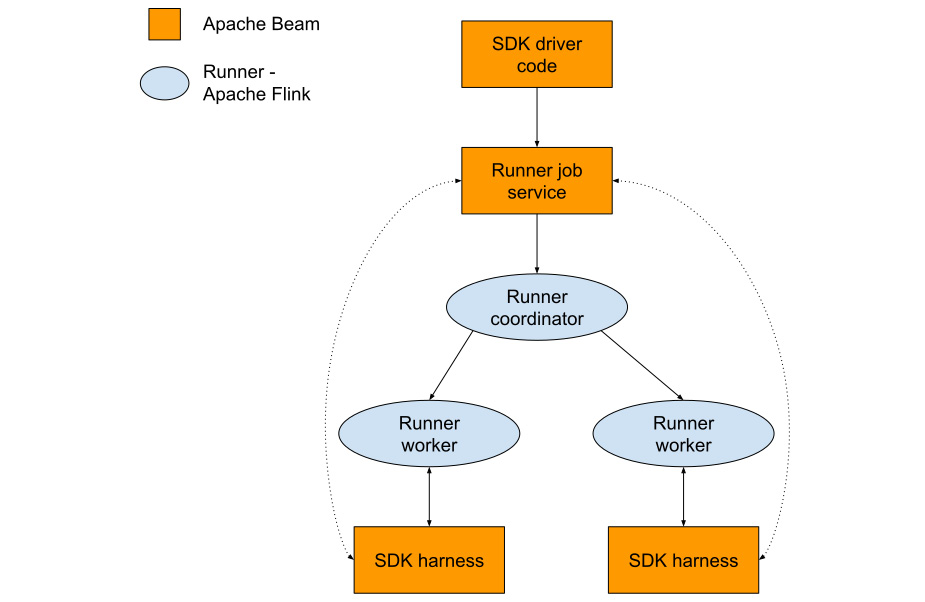
As we can see, the architecture consists of two types of components – Apache Beam components and Runner components. In this case, a Runner is a piece of technology that performs the actual execution – it may be Apache Flink, Apache Spark, Google Cloud Dataflow, or any other supported Runner. Each of these Runners typically has a coordinator that needs to receive a job submission and use this submission to create work for worker nodes. By doing this, it can orchestrate its execution. This coordinator typically uses a language-dependent API, depending on which technology the Runner is based on. The majority of open-source Runners use Java, as is the case for Apache Flink. The Flink coordinator is called JobManager and expects to receive a Java JAR file for execution. When it receives the JAR, it sends it to the workers, along with the graph of transforms that represent its computation. This graph contains transforms, which, in turn, contain User-Defined Functions (UDFs), which is user code that needs to be executed (for instance, a mapping function that converts lines of text into words).
So, we have two problems to solve:
- How will the non-native SDK (let’s say, the Python SDK for Java Runner) convert the Beam Python pipeline into a Java JAR that is understood by the Runner?
- How will the Runner worker nodes execute in Java non-native (again, Python) user code?
To solve both these problems, Apache Beam has created services that fill the gaps where needed. These components are called portable pipeline representation, Job Service, and SDK harness.
Job Service
The main task of Job Service is to receive the portable representation of the pipeline and convert it into the format that is understood by a particular Runner. This means that each supported Runner (Apache Flink, Apache Spark, Google Cloud Dataflow, and so on) has to have its own Job Service. This Job Service must create the submitted job in such a way that it replaces calls to UDFs with calls to the SDK harness process. It must also instruct the Runner coordinator to create an SDK harness process for each worker.
SDK harness
The SDK harness is the last missing piece of the puzzle – once the code that’s executing on the Runner worker needs to call the UDFs, it delegates the call to the harness using gRPC – an HTTP/2 based protocol that relies on protocol buffers as its serialization mechanism. The harness is specific to each SDK, which means that every new SDK must provide a harness that will execute UDFs for the Runner. The harness will obtain the necessary data from Job Service (strictly speaking, Artifact Service, but that is a technical detail) – for example, the Python script that was used to run the job.
This completes the cycle. To support the new SDK, we have to do the following:
- Provide a way to create a portable pipeline representation from the SDK-dependent pipeline description.
- Provide an SDK harness that accepts a portable description of the UDF and executes it.
- On the other hand, when creating a new Runner, all we have to care about is converting the portable pipeline representation into the Runner’s API. Therefore, the Runner does not have to know anything about the Apache Beam SDKs and, at the same time, the SDKs do not have to know anything about the existing Runners. All these parts are completely separated, which is what makes the approach truly portable.